Search engines have two main functions, searching the network and building indexes; with this, they provide you with answers through a relevance calculation and thus show you optimal results. Which makes us question? How do search engines work? And it is not that there is some “secret” in operation, but it will give us a rough overview of better understanding what these tools are and what we can expect from them. What is a search engine? Search engines are very complicated applications that are constantly being updated.
A search engine is a software or program that locates content on the Internet in a fast and very efficient way and then, based on your search requests, present us the results that it has previously stored in its database or index. The key is how they build their database and then categorize the results they are going to show to their users. A particular example of some of the well-known search engines you have used is Google, Bing, Yahoo!, and maybe Ask. How does a search engine work? Simplifying the introductory concept, a search engine consists of four essential parts:
*An interface for the client to make search demands
*A robot or a spider that looks for data on the Internet
*An algorithm that associates client solicitations to the data set
*And a database where all of the records have been indexed
The heart of it all
Search Engine It is undoubtedly the algorithm that directs the robot or spider and then categorizes the information displayed after user requests. These calculations are genuinely perplexing, and their structure and activity rely directly upon their designers. However, the algorithm is useless if the search engine does not fulfil two other functions:
*Collect the information using web crawling techniques
*Store and index the information
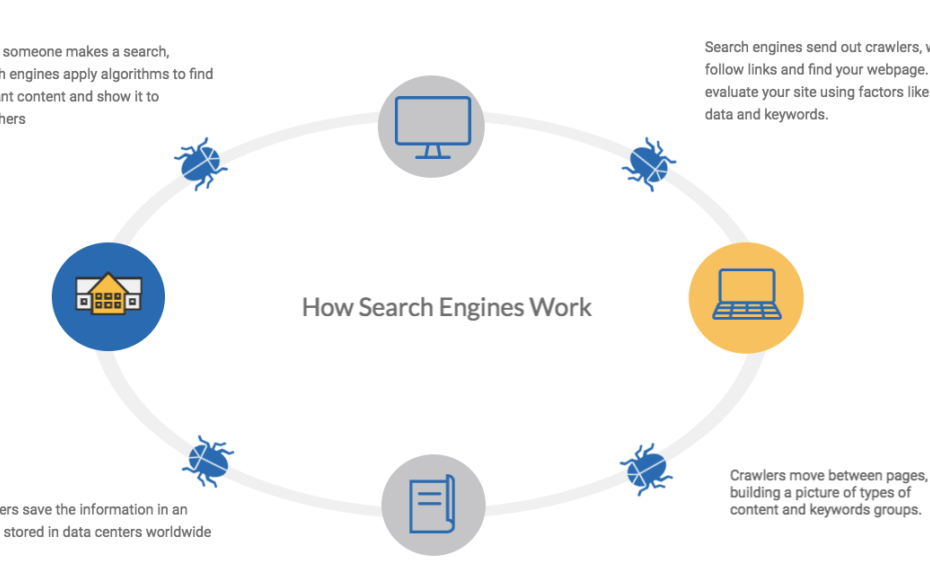
The engines create lists of web pages using their spiders or robots through web crawling techniques and then organize the information found, creating indexes of the web contents.
How does web crawling work?
The search engines find the information using a robot or web crawler; basically, what you do is enter a website to collect some data, identify the links on the website and finally follow these links as would a user to repeat the process over and again. In this way, the web crawler jumps from one link to another and navigates through different pages from which it collects data and feeds it to its database. This is the way a search engine finds information. Then it is time to index the information. How is the information indexed? Once the robot or spider, also known as a web crawler, finds the information, an index is created with the essential information of the web page is stored in its database, and that will only be shown when we perform a search in the engine. In relation to the quality of the results shown by the search engine, of course, the type of request that is made will depend on choosing the most appropriate search engine for each occasion, basically on the algorithm. The better or worse the algorithm is, the quality of the search engine results will also depend. Hence it is the most crucial part of search engines.
{kind=link}